
这篇主要讲讲 LevelDB 是如何组织和存储数据的。先搞明白整体结构,然后再去看具体的实现细节,我觉得这种自顶向下的方式是一个比较好的顺序
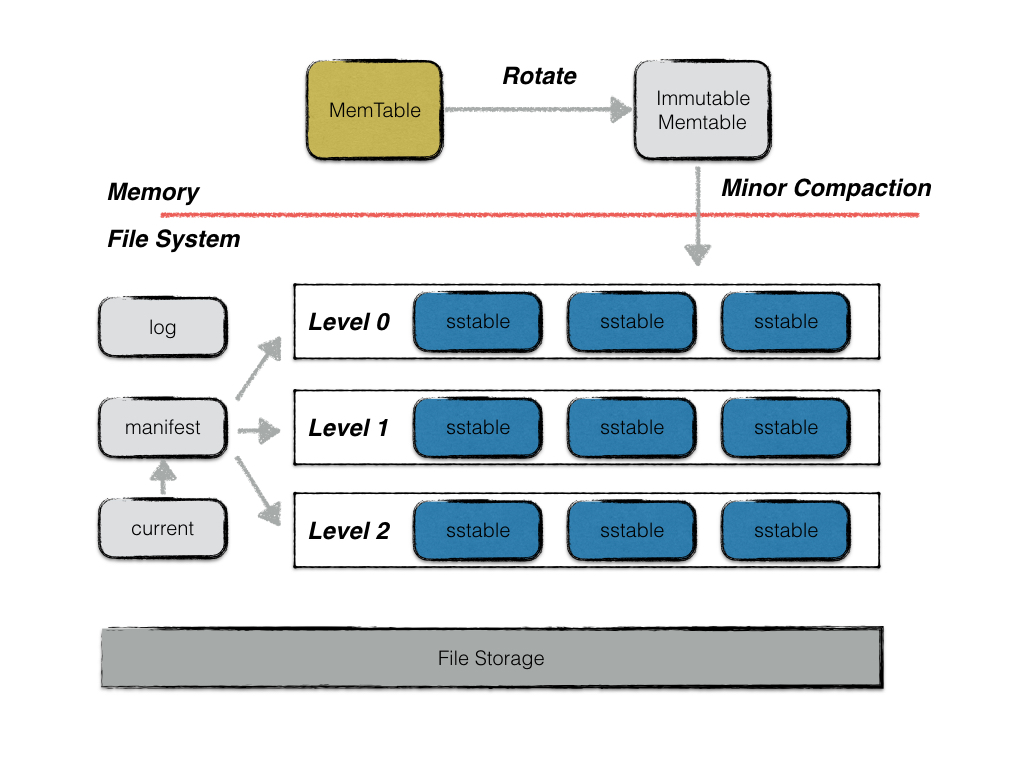
首先复习一下下面这张图:
然后再请阅读一下官方在 GitHub 上给的几篇说明
。现在写博客的时候才发现,官方在 doc/ 下的文档其实已经将 LevelDB 相关的存储格式介绍了一遍,本文会基于这些内容再进行整理。先简单说一下整体的写流程:
- LevelDB 在写数据时,会先在日志中添加一个 Record,然后将数据插入到 MemTable 中
- 如果 MemTable 满了,就会将其转换为不可变的 MemTable,并生成一个新的空的 MemTable 继续写入
- 后台线程会将不可变的 MemTable 刷写到磁盘上,形成一个 Level 0 的 SSTable 文件
- 当 Level 0 的 SSTable 文件数量超过一定阈值时,后台线程会触发 Compaction,将 Level 0 的 SSTable 文件与 Level 1 的 SSTable 文件进行合并,得到 Level 1 的 SSTable 文件
- 类似的,后续 Level 的 SSTable 文件也会在达到一定数量后触发 Compaction
这篇文章先将涉及到的所有数据的格式做个介绍
LOG
LevelDB 的日志文件(Write-Ahead Log)用于数据持久化和故障恢复。Log 文件由一系列 32KB 的 Block(块)组成(最后一个 Block 可能小于 32KB)。每个 Block 包含多个 Record(记录),每个 Record 存储实际的数据条目

可以发现在每个 Block 的末尾,可能未被 Record 填满。如果剩余空间不足 7 字节(Record 头部大小),则该空间会作为 Trailer 被填充为 0。那 Record 的结构是怎么样的呢?首先,Record 头部占用 7 字节,包含以下字段:
- Length(2 字节):表示 Record 数据的长度
- Type(1 字节):表示 Record 的类型,有
FULL、FIRST、MIDDLE、LAST四种类型 - CRC(4 字节):用于校验 Record 数据的完整性
- Data(可变长度):实际存储的数据
这里的 Data 实际上是 WriteBatch。它的格式在 db/write_batch.cc
中有说明:
WriteBatch::rep_ :=
sequence: fixed64
count: fixed32
data: record[count]
record :=
kTypeValue varstring varstring |
kTypeDeletion varstring
varstring :=
len: varint32
data: uint8[len]MemTable
MemTable 是一个内存的数据结构,用于存储最近写入的数据。
class MemTable {
...
private:
typedef SkipList<const char*, KeyComparator> Table;
...
Arena arena_;
Table table_;
};其中 Arena 负责数据的内存分配,所有的 KV 对由跳表进行组织。跳表的每个 entry 结构如下:
key_size : varint32 of internal_key.size()
key bytes : char[internal_key.size()]
tag : uint64((sequence << 8) | type)
value_size : varint32 of value.size()
value bytes : char[value.size()]
跳表在插入新数据时,会根据 key_size 拿到的 InternalKey 来进行排序,这个 InternalKey 的结构如下:
user_key : char[user_key.size()]
sequence : uint64
type : uint8具体的排序规则为:
- 按 user_key 递增排序(使用用户提供的 comparator,通常是 BytewiseComparator)
- 如果 user_key 相同,按 sequence number 递减排序(新的排前面)
- 按 type 递减排序(Put=1, Delete=0,Put 排前面)
当 MemTable 写入的数据占用内存到达指定大小 (Options.write_buffer_size),则自动转换为 Immutable MemTable(只读),同时生成新的 MemTable 供写操作写入新数据。后台的 Compact 进程会负责将 Immutable MemTable dump to disk 生成 SSTable
SSTable
SSTable(Sorted String Table)是 LevelDB 用于持久化存储数据的文件格式。每个 SSTable 文件包含多个 Block(块),每个 Block 存储多个有序的 key-value 对,默认每个 Block 的大小为 4KB。Block 除了存储实际数据外,还会存储两个额外字段:
- 压缩类型
- CRC 校验码

在一个 SSTable 中,根据数据的组织形式,可以将其划分为以下几个部分:
- 数据块(Data Blocks):存储实际的 key-value 对
- Filter 块(Filter Block):用于快速判断某个 key 是否存在于 SSTable 中,通常使用布隆过滤器实现
- metaindex 块(Metaindex Block):存储 SSTable 中其他块的元数据信息
- 索引块(Index Block):存储数据块的索引信息,用于快速定位数据块
- Footer(文件尾部):包含 SSTable 的元数据信息,如索引块和 metaindex 块的位置
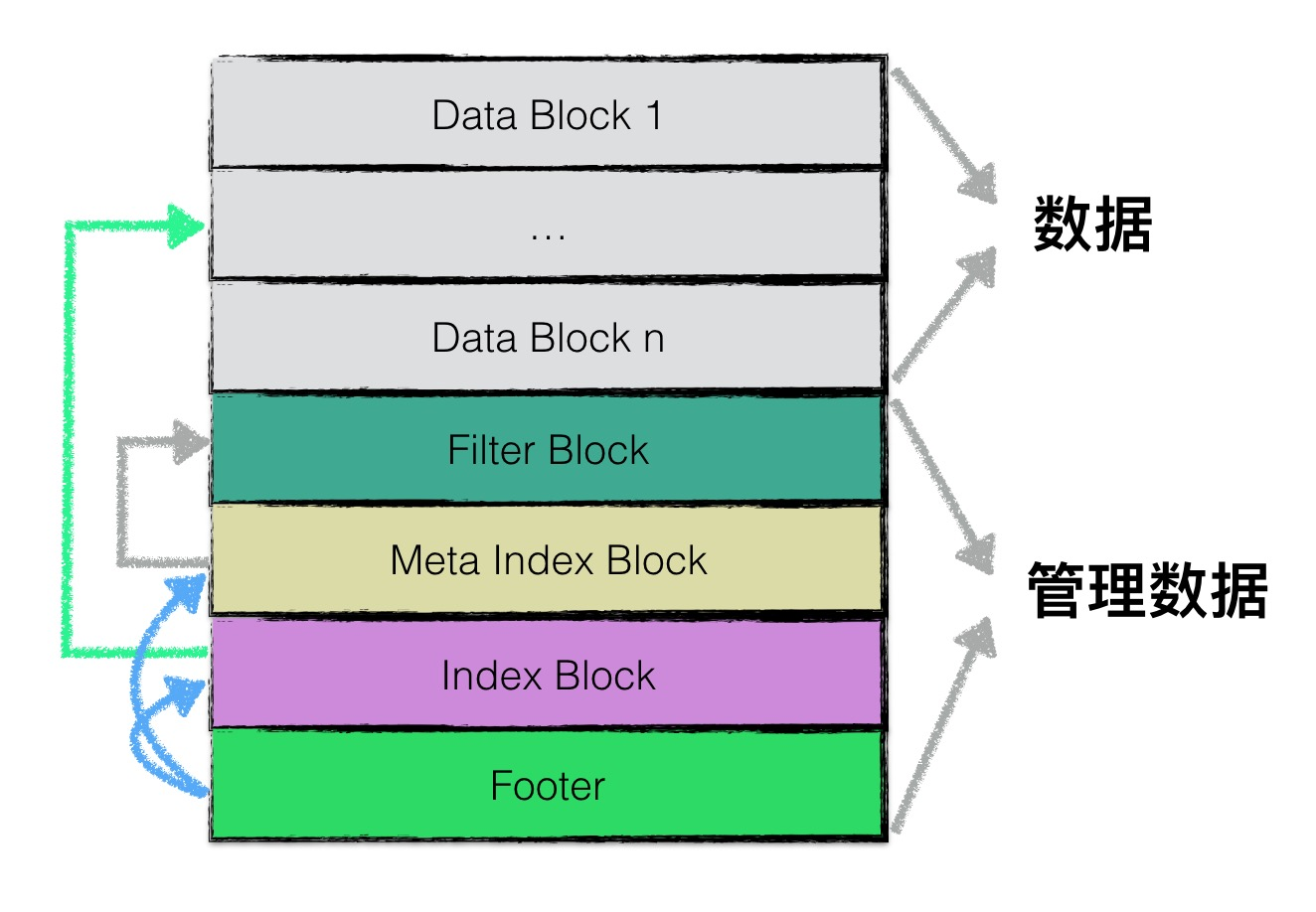
这里空间不够写不下 可以去看 handbook
,有图有说明,讲的听清楚的
Manifest
Manifest 文件是 LevelDB 中用来记录数据库版本信息和文件元数据的重要文件。这部分我还没看完,后续补充。可以先看 handbook