
今天开始记录一下学习 LevelDB 的笔记。虽说网上已经有很多相关资料,但还是想自己动手整理一下,加深理解,同时方便查阅。所以有的地方可能不会说的特别细,读者请自行搜索。本系列目录如下:
- 0x00 开篇
- 0x01 基本工具和数据结构
- To be continued…
本篇作为系列的第一篇,主要介绍 LevelDB 的基本概念和操作
首先来聊聊 LevelDB 是干什么的。与 MySQL、Redis 这些传统数据库不同,LevelDB 是一个键值存储数据库。它由 Google 开发,主要用于 存储大量数据,并且以高效的写性能著称。LevelDB 采用了 LSM Tree(Log-Structured Merge Tree)作为其底层数据结构,这使得它在处理大量写操作时表现出色。下表简要给出三者的对比:
| 名称 | 存储形式 | 场景 |
|---|---|---|
| MySQL | 关系型数据存储 | 复杂查询,比如电商系统 |
| Redis | 内存数据存储 | 高性能缓存,消息队列等场景 |
| LevelDB | 键值存储 | 大规模数据存储,如浏览器缓存、区块链数据存储等 |
提示
其实现在 RocksDB 更流行一些,但是代码量太大了。LevelDB 作为 RocksDB 的前身,代码相对简洁,更适合学习,所以先从 LevelDB 入手吧~
基本概念和架构
先从整体入手,有个印象。
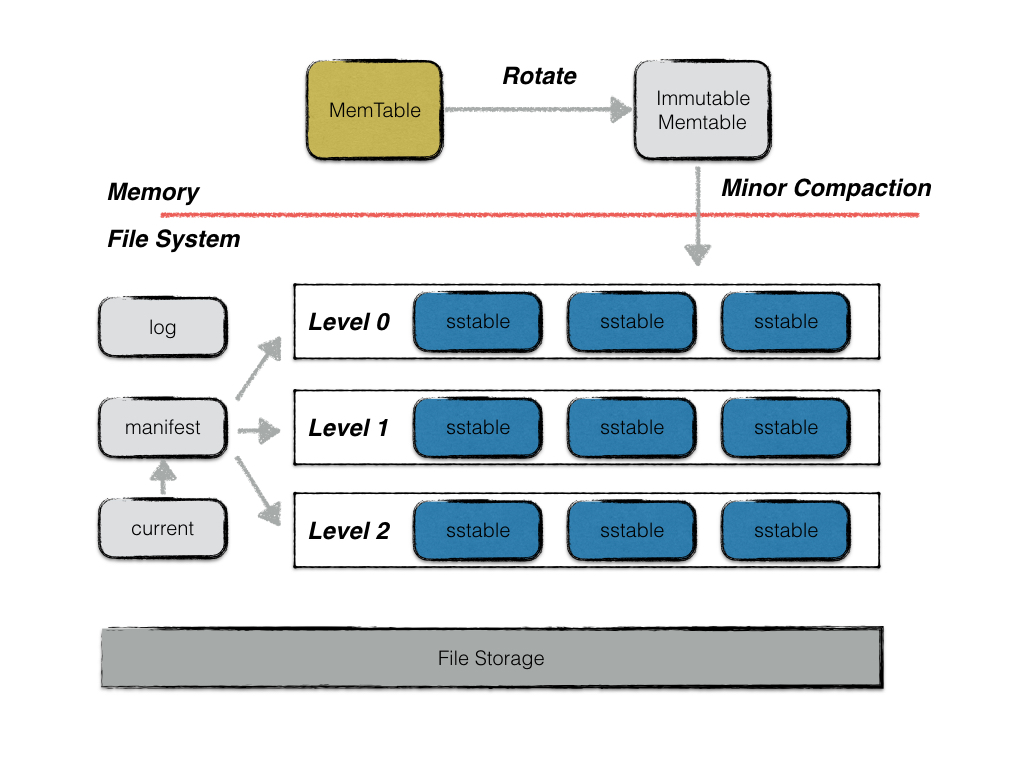
LevelDB 主要由以下部分组成:
- MemTable:MemTable(内存表)是数据写入的第一站。所有新的写入操作,无论是插入、更新还是删除,都会首先被记录到这个驻留在内存的跳表中。它就像系统的高速缓存区,提供了极快的随机写入和读取能力,确保最新的数据能被瞬时访问。其内部按键有序排列的特性,也为后续的高效查找和持久化奠定了基础
- Immutable MemTable:当 MemTable 增长到一定大小时,LevelDB 会将其转换为 Immutable MemTable(不可变内存表)。这是一个非常巧妙的设计,它意味着这个内存表变成了一个只读的、冻结的版本。此时,系统会立即创建一个新的空 MemTable 来接收后续的写入请求,而那个被冻结的 Immutable MemTable 则由后台线程负责将其内容安全地、异步地写入磁盘。这个转换过程几乎是瞬间完成的,它巧妙地实现了读写分离,前台写入不会被后台的持久化I/O操作阻塞
- Log:为了保证数据的持久性,LevelDB 采用了 Write-Ahead Log(预写日志,通常简称为 Log 或 Journal) 机制。每一次数据写入,都会在真正修改内存中的 MemTable 之前,被追加写入到一个顺序的日志文件中。这个日志是系统崩溃恢复的“救命稻草”,即使系统意外宕机,MemTable 中的数据丢失,在重启时也能通过重放这个日志文件,完整地重建出崩溃前的内存表状态,从而确保已确认的写入不会丢失
- SSTable:当 Immutable MemTable 被后台线程持久化到磁盘时,它便转换为了 SSTable(Sorted String Table,有序字符串表)。SSTable 是 LevelDB 在磁盘上存储数据的最终形态,它是一个不可变的、内部按键有序排列的数据文件。LevelDB 会通过“层级压缩”过程,将大量小型的 SSTable 文件逐步合并、整理为更大型且有序的文件,并放置在不同的层级中。这种设计极大地优化了范围查询的效率,并且通过后台的合并过程,持续回收过期或重复的数据,控制存储空间的膨胀
- Manifest:随着数据文件的不断增删与合并,数据库的文件构成时刻在变化。Manifest(清单文件) 就像一本详尽的数据库“编年史”,它忠实记录了每一次SSTable文件的变更——哪些文件被新增,哪些文件被删除。它本质上是一个追加写入的日志,保存了数据库在任意时间点的完整“快照”版本信息,确保系统在任何时候都能知道应该从哪些文件中去查找数据,是保证数据视图一致性的基石
- Current:最后,在众多不断生成的 Manifest 文件中,Current(当前文件) 扮演了一个轻量级“指针”的角色。它本身不存储任何元数据,其内容仅仅是一个简单的字符串,指明了当前应该使用哪一个 Manifest 文件。在数据库启动时,系统首先读取这个 Current 文件,就能立刻定位到最新的、正确的元数据版本,从而快速完成初始化。这个简单的设计,优雅地解决了元数据版本定位的问题,是整个恢复流程的起点
如何安装
既然是学习,那就从源码开始安装,LevelDB 的源码托管在 GitHub 上,代码克隆下来,跟着 README 的步骤即可安装。我是在 WSL2 的 Ubuntu 环境下安装的,工具链是 Clang 18.1.3,在构建时遇到了报错,通过对下面两处位置进行修改解决了问题,仅供参考:
diff --git a/util/env_posix.cc b/util/env_posix.cc
index c249032..dbaaa51 100644
--- a/util/env_posix.cc
+++ b/util/env_posix.cc
@@ -874,7 +874,8 @@ class SingletonEnv {
#endif // !defined(NDEBUG)
static_assert(sizeof(env_storage_) >= sizeof(EnvType),
"env_storage_ will not fit the Env");
- static_assert(std::is_standard_layout_v<SingletonEnv<EnvType>>);
+ static_assert(std::is_standard_layout<SingletonEnv<EnvType>>::value,
+ "SingletonEnv must be standard-layout");
static_assert(
offsetof(SingletonEnv<EnvType>, env_storage_) % alignof(EnvType) == 0,
"env_storage_ does not meet the Env's alignment needs");
diff --git a/util/no_destructor.h b/util/no_destructor.h
index c28a107..147a54c 100644
--- a/util/no_destructor.h
+++ b/util/no_destructor.h
@@ -21,7 +21,8 @@ class NoDestructor {
explicit NoDestructor(ConstructorArgTypes&&... constructor_args) {
static_assert(sizeof(instance_storage_) >= sizeof(InstanceType),
"instance_storage_ is not large enough to hold the instance");
- static_assert(std::is_standard_layout_v<NoDestructor<InstanceType>>);
+ static_assert(std::is_standard_layout<NoDestructor<InstanceType>>::value,
+ "NoDestructor must be standard-layout");
static_assert(
offsetof(NoDestructor, instance_storage_) % alignof(InstanceType) == 0,
"instance_storage_ does not meet the instance's alignment requirement");
初步照面
学习一个新组件,从常用接口入手是一个不错的选择。该怎么学习接口呢?直接让 AI 写段代码看看吧,有个整体印象,还能顺便调试一下。下面是生成的代码:
#include <cassert>
#include <chrono>
#include <iostream>
#include <string>
#include "leveldb/db.h"
#include "leveldb/env.h"
#include "leveldb/filter_policy.h"
#include "leveldb/options.h"
#include "leveldb/write_batch.h"
class LevelDBDemo {
public:
LevelDBDemo(const std::string& db_path) : db_path_(db_path), db_(nullptr) {}
~LevelDBDemo() { Close(); }
// 1. 打开数据库
bool Open() {
leveldb::Options options;
options.create_if_missing = true; // 不存在时创建
options.error_if_exists = false; // 存在时不报错
options.write_buffer_size = 4 * 1024 * 1024; // 4MB写缓冲区
options.max_file_size = 2 * 1024 * 1024; // 2MB SST文件
options.block_size = 4 * 1024; // 4KB块大小
options.compression = leveldb::kSnappyCompression; // 压缩
options.filter_policy = leveldb::NewBloomFilterPolicy(10); // 布隆过滤器
leveldb::Status status = leveldb::DB::Open(options, db_path_, &db_);
if (!status.ok()) {
std::cerr << "打开数据库失败: " << status.ToString() << std::endl;
return false;
}
std::cout << "✓ 数据库打开成功: " << db_path_ << std::endl;
return true;
}
// 2. 关闭数据库
void Close() {
if (db_) {
delete db_;
db_ = nullptr;
std::cout << "✓ 数据库已关闭" << std::endl;
}
}
// 3. 基本Put操作
bool Put(const std::string& key, const std::string& value) {
leveldb::WriteOptions write_options;
write_options.sync = false; // 异步写入,性能更好
leveldb::Status status = db_->Put(write_options, key, value);
if (!status.ok()) {
std::cerr << "Put失败: " << status.ToString() << std::endl;
return false;
}
return true;
}
// 4. 基本Get操作
bool Get(const std::string& key, std::string* value) {
leveldb::ReadOptions read_options;
read_options.verify_checksums = false; // 不验证校验和,更快
read_options.fill_cache = true; // 填充缓存
leveldb::Status status = db_->Get(read_options, key, value);
if (status.IsNotFound()) {
std::cout << "键未找到: " << key << std::endl;
return false;
} else if (!status.ok()) {
std::cerr << "Get失败: " << status.ToString() << std::endl;
return false;
}
return true;
}
// 5. 基本Delete操作
bool Delete(const std::string& key) {
leveldb::WriteOptions write_options;
leveldb::Status status = db_->Delete(write_options, key);
if (!status.ok()) {
std::cerr << "Delete失败: " << status.ToString() << std::endl;
return false;
}
return true;
}
// 6. 批量写入操作(原子性)
bool BatchWrite() {
leveldb::WriteBatch batch;
// 批量添加Put操作
batch.Put("batch_key1", "batch_value1");
batch.Put("batch_key2", "batch_value2");
batch.Put("batch_key3", "batch_value3");
// 批量添加Delete操作
batch.Delete("batch_key1"); // 立即删除刚添加的
// 执行批量写入
leveldb::WriteOptions write_options;
write_options.sync = true; // 同步写入,保证持久化
leveldb::Status status = db_->Write(write_options, &batch);
if (!status.ok()) {
std::cerr << "批量写入失败: " << status.ToString() << std::endl;
return false;
}
std::cout << "✓ 批量写入完成" << std::endl;
return true;
}
// 7. 迭代器遍历
void IteratorDemo() {
std::cout << "\n=== 迭代器遍历 ===" << std::endl;
leveldb::ReadOptions read_options;
read_options.snapshot = db_->GetSnapshot(); // 使用快照,保证一致性视图
// 创建迭代器
leveldb::Iterator* it = db_->NewIterator(read_options);
// 正向遍历
std::cout << "正向遍历:" << std::endl;
for (it->SeekToFirst(); it->Valid(); it->Next()) {
std::cout << " " << it->key().ToString() << " => " << it->value().ToString() << std::endl;
}
// 反向遍历
std::cout << "\n反向遍历:" << std::endl;
for (it->SeekToLast(); it->Valid(); it->Prev()) {
std::cout << " " << it->key().ToString() << " => " << it->value().ToString() << std::endl;
}
// 范围查询
std::cout << "\n范围查询 [key1, key5]:" << std::endl;
it->Seek("key1");
while (it->Valid() && it->key().ToString() <= "key5") {
std::cout << " " << it->key().ToString() << " => " << it->value().ToString() << std::endl;
it->Next();
}
// 清理
db_->ReleaseSnapshot(read_options.snapshot);
delete it;
}
// 8. 快照使用
void SnapshotDemo() {
std::cout << "\n=== 快照演示 ===" << std::endl;
// 创建快照
const leveldb::Snapshot* snapshot = db_->GetSnapshot();
// 在快照之后写入新数据
Put("snapshot_key", "value_after_snapshot");
// 用快照读取(应该看不到新数据)
leveldb::ReadOptions snapshot_options;
snapshot_options.snapshot = snapshot;
std::string value;
leveldb::Status status = db_->Get(snapshot_options, "snapshot_key", &value);
if (status.IsNotFound()) {
std::cout << "快照中未找到新写入的键" << std::endl;
}
// 释放快照
db_->ReleaseSnapshot(snapshot);
std::cout << "✓ 快照已释放" << std::endl;
}
// 9. 获取属性
void GetPropertyDemo() {
std::cout << "\n=== 数据库属性 ===" << std::endl;
std::string value;
if (db_->GetProperty("leveldb.stats", &value)) {
std::cout << "统计信息:\n" << value << std::endl;
}
if (db_->GetProperty("leveldb.sstables", &value)) {
std::cout << "SSTables信息:\n" << value << std::endl;
}
if (db_->GetProperty("leveldb.approximate-memory-usage", &value)) {
std::cout << "内存使用: " << value << std::endl;
}
}
// 10. 手动压缩
void CompactRangeDemo() {
std::cout << "\n=== 手动压缩 ===" << std::endl;
// 压缩指定键范围
leveldb::Slice start("key1");
leveldb::Slice end("key9");
db_->CompactRange(&start, &end);
std::cout << "✓ 键范围 [" << start.ToString() << ", " << end.ToString() << "] 已压缩" << std::endl;
}
// 11. 获取数据库大小估算
void GetApproximateSizesDemo() {
std::cout << "\n=== 数据库大小估算 ===" << std::endl;
leveldb::Range ranges[2];
ranges[0] = leveldb::Range("a", "m");
ranges[1] = leveldb::Range("m", "z");
uint64_t sizes[2];
db_->GetApproximateSizes(ranges, 2, sizes);
std::cout << "范围 [a, m) 大约: " << sizes[0] << " 字节" << std::endl;
std::cout << "范围 [m, z) 大约: " << sizes[1] << " 字节" << std::endl;
}
// 12. 调试:检查键是否存在
bool KeyExists(const std::string& key) {
std::string value;
leveldb::Status status = db_->Get(leveldb::ReadOptions(), key, &value);
return status.ok();
}
// 13. 清空所有数据(危险操作)
bool ClearAll() {
leveldb::WriteBatch batch;
// 遍历并删除所有键
leveldb::Iterator* it = db_->NewIterator(leveldb::ReadOptions());
for (it->SeekToFirst(); it->Valid(); it->Next()) {
batch.Delete(it->key().ToString());
}
delete it;
leveldb::WriteOptions write_options;
write_options.sync = true;
leveldb::Status status = db_->Write(write_options, &batch);
if (!status.ok()) {
std::cerr << "清空数据失败: " << status.ToString() << std::endl;
return false;
}
std::cout << "✓ 所有数据已清空" << std::endl;
return true;
}
// 运行完整演示
void RunDemo() {
if (!Open()) {
return;
}
std::cout << "\n=== LevelDB 接口演示 ===" << std::endl;
// 测试基本操作
std::cout << "\n1. 基本操作测试:" << std::endl;
// 写入一些测试数据
Put("key1", "value1");
Put("key2", "value2");
Put("key3", "value3");
Put("key4", "value4");
Put("key5", "value5");
// 读取测试
std::string value;
if (Get("key3", &value)) {
std::cout << "读取 key3: " << value << std::endl;
}
// 更新操作
Put("key3", "updated_value3");
if (Get("key3", &value)) {
std::cout << "更新后 key3: " << value << std::endl;
}
// 删除测试
Delete("key4");
if (!Get("key4", &value)) {
std::cout << "key4 已删除" << std::endl;
}
// 运行各个功能演示
BatchWrite();
IteratorDemo();
SnapshotDemo();
GetPropertyDemo();
GetApproximateSizesDemo();
CompactRangeDemo();
// 性能测试
PerformanceTest();
// 清理
ClearAll();
}
// 性能测试
void PerformanceTest() {
std::cout << "\n=== 性能测试 ===" << std::endl;
auto start = std::chrono::high_resolution_clock::now();
// 写入性能测试
leveldb::WriteBatch batch;
const int NUM_WRITES = 1000;
for (int i = 0; i < NUM_WRITES; ++i) {
batch.Put("perf_key_" + std::to_string(i), "perf_value_" + std::to_string(i));
}
leveldb::WriteOptions write_options;
write_options.sync = false; // 异步以获得更好性能
db_->Write(write_options, &batch);
auto end = std::chrono::high_resolution_clock::now();
auto duration = std::chrono::duration_cast<std::chrono::milliseconds>(end - start);
std::cout << "写入 " << NUM_WRITES << " 条记录耗时: " << duration.count() << "ms" << std::endl;
std::cout << "平均每条: " << (duration.count() * 1000.0 / NUM_WRITES) << "us" << std::endl;
}
private:
std::string db_path_;
leveldb::DB* db_;
};
int main(int argc, char* argv[]) {
// 设置数据库路径
std::string db_path = "./test_leveldb";
// 移除旧的数据库文件(如果有)
leveldb::DestroyDB(db_path, leveldb::Options());
// 创建并运行演示
LevelDBDemo demo(db_path);
demo.RunDemo();
std::cout << "\n=== 演示完成 ===" << std::endl;
std::cout << "可以检查数据库文件: " << db_path << std::endl;
return 0;
}上面出现的相关接口包括:
- 打开数据库(
leveldb::DB::Open) - 关闭数据库(
delete db) - 基本的 Put/Get/Delete 操作(
db->Put,db->Get,db->Delete) - 批量写入(
leveldb::WriteBatch) - 迭代器遍历(
db->NewIterator) - 快照使用(
db->GetSnapshot) - 获取属性(
db->GetProperty) - 手动压缩(
db->CompactRange) - 获取数据库大小估算(
db->GetApproximateSizes)
下面先看看 LevelDB 存了哪些文件,然后针对几个主要的操作先看看实现函数,从而对 LevelDB 中的相关类和函数有个初步印象
LevelDB 存了哪些文件
跑完上面的测试,会发现 LevelDB 生成了如下的 6 个文件,现在只需要了解一下大概的作用:
test_leveldb
├── 000004.log // 预写日志文件,负责记录所有写入操作,用于崩溃恢复
├── 000005.ldb // SSTable 数据文件
├── CURRENT // 当前使用的 Manifest
├── LOCK // 用于进程间互斥访问
├── LOG // 内部运行日志,记录各种信息、警告等
└── MANIFEST-000002 // 数据文件的增删和层级结构等关键元数据打开数据库
打开数据库的接口长这样:
Status DB::Open(const Options& options, const std::string& dbname, DB** dbptr);这个函数接受一个 options 和 dbname,将得到的数据库指针赋值到 dbptr,函数的返回值是 Status。先来看看这个 Options 有哪些内容吧(位于 include/leveldb/options.h):
| 成员变量 | 含义 |
|---|---|
| comparator | DB 中 key 的比较方式,默认为 BytewiseComparator |
| create_if_missing | 如果 DB 不存在就创建一个新的 |
| error_if_exists | 如果 DB 已经存在了打开时会返回错误 |
| paranoid_checks | 启用严格检查,如果处理数据时发生错误会立即停止 |
| env | 抽象的环境接口,统一 Windows&Linux 上相关的操作 |
| info_log | 如果非空的话,DB产生的中间日志信息会记录在这里 |
| write_buffer_size | 内存中的写缓冲区大小,越大性能越好,但在下次打开 DB 时会增加 recovery 的时间 |
| max_open_files | DB 可同时打开的最大文件数,默认为 1000 |
| block_cache | 数据会以 block 的形式进行组织管理。如果为空,leveldb 会自动创建一个 8MB 大小的内部 cache |
| block_size | 块大小。这个参数可以动态调整 |
| block_restart_interval | 在键的增量编码中,两个重启点之间包含的键的数量,默认为 16 |
| max_file_size | 文件的最大尺寸(其实就是 SST 文件的大小) |
| compression | 对 block 采用什么压缩算法,可选的有不压缩,snappy 以及 zstd |
| zstd_compression_level | zstd 的压缩等级 |
| reuse_logs | (实验性)若设置为 true,在打开 DB 时复用已有 MANIFEST 和日志文件 |
| filter_policy | 默认为空。可设置为布隆过滤器来减少磁盘的读次数 |
好的,如果是第一次看的话,相信你头都要大了。等到把我这个系列看完,你就全都理解了。现在只是留个印象,先不深入解释。下面看看 Open 这个接口的具体实现
Status DB::Open(const Options& options, const std::string& dbname, DB** dbptr) {
*dbptr = nullptr;
DBImpl* impl = new DBImpl(options, dbname); // 1. 创建数据库内部实现实例
impl->mutex_.Lock(); // 2. 加锁,保护后续初始化过程的原子性
VersionEdit edit; // 3. 创建版本编辑对象,用于记录本次启动的变更
// Recover handles create_if_missing, error_if_exists
bool save_manifest = false;
// 4. 关键:执行数据库恢复。如果数据库存在则加载数据,如果不存在且设置create_if_missing则会创建新库
Status s = impl->Recover(&edit, &save_manifest);
// 5. 如果恢复成功,但当前内存表为空(例如是新数据库,或所有数据已持久化),则需创建新的日志文件和内存表
if (s.ok() && impl->mem_ == nullptr) {
// Create new log and a corresponding memtable.
uint64_t new_log_number = impl->versions_->NewFileNumber();
WritableFile* lfile;
s = options.env->NewWritableFile(LogFileName(dbname, new_log_number),
&lfile);
if (s.ok()) {
edit.SetLogNumber(new_log_number); // 记录新日志文件号到版本编辑
impl->logfile_ = lfile; // 持久的日志文件
impl->logfile_number_ = new_log_number;
impl->log_ = new log::Writer(lfile); // 日志写入器
impl->mem_ = new MemTable(impl->internal_comparator_); // 新的内存表
impl->mem_->Ref();
}
}
// 6. 如果需要保存清单(通常在恢复过程中有数据变更),则将版本编辑应用到当前版本
if (s.ok() && save_manifest) {
edit.SetPrevLogNumber(0); // 恢复后,不再需要旧的日志文件
edit.SetLogNumber(impl->logfile_number_);
s = impl->versions_->LogAndApply(&edit, &impl->mutex_); // 持久化元数据变更
}
// 7. 清理无用文件,并可能触发后台压缩
if (s.ok()) {
impl->RemoveObsoleteFiles();
impl->MaybeScheduleCompaction(); // 不立即执行,只是安排任务
}
impl->mutex_.Unlock();
// 8. 最终处理:成功则返回实例指针,失败则清理资源
if (s.ok()) {
assert(impl->mem_ != nullptr);
*dbptr = impl;
} else {
delete impl;
}
return s;
}对照注释可以先看个大概,这里面主要涉及了 DBImpl、VersionEdit 等类,以及 manifest、recover、log_number 等概念,其中的加锁解锁时机也可能是一个值得探究的点
关闭数据库
看看 DBImpl 的析构函数长什么样
DBImpl::~DBImpl() {
// Wait for background work to finish.
mutex_.Lock();
shutting_down_.store(true, std::memory_order_release);
while (background_compaction_scheduled_) {
background_work_finished_signal_.Wait();
}
mutex_.Unlock();
if (db_lock_ != nullptr) {
env_->UnlockFile(db_lock_);
}
delete versions_;
if (mem_ != nullptr) mem_->Unref();
if (imm_ != nullptr) imm_->Unref();
delete tmp_batch_;
delete log_;
delete logfile_;
delete table_cache_;
if (owns_info_log_) {
delete options_.info_log;
}
if (owns_cache_) {
delete options_.block_cache;
}
}这里可以看出,LevelDB 应该有后台的 compation 任务,在析构时要提醒这些任务,然后才能继续析构其他成员。这里的 delete 顺序应该也是有讲究的。
基本的读写操作
LevelDB 是一个基于 LSM Tree 的数据库,Put 和 Delete 都是先添加一条记录,真实的修改行为要到落盘时在处理。在实现上,这两个接口最终都通过组成 WriteBatch,然后用 Write 函数实现具体的细节
Status DBImpl::Write(const WriteOptions& options, WriteBatch* updates) {
// 1. 创建一个写者对象,封装本次写入的请求
Writer w(&mutex_);
w.batch = updates;
w.sync = options.sync; // 是否要求同步刷盘
w.done = false; // 完成标志
// 2. 加锁进入临界区
MutexLock l(&mutex_);
// 将当前写者加入等待队列尾部
writers_.push_back(&w);
// 3. 等待成为队首或被前一个写者完成
// 如果不是队首且未完成,则等待条件变量唤醒
while (!w.done && &w != writers_.front()) {
w.cv.Wait();
}
// 4. 如果已被前一个写者完成(批处理合并),直接返回结果
if (w.done) {
return w.status;
}
// 5. 至此,当前写者已是队首,开始处理写入
// 可能需要临时解锁等待(如memtable已满需刷盘或压缩)
Status status = MakeRoomForWrite(updates == nullptr);
uint64_t last_sequence = versions_->LastSequence();
Writer* last_writer = &w; // 记录本批次最后处理的写者
// 6. 如果updates不为空(非压缩触发的写入),执行实际的写入逻辑
if (status.ok() && updates != nullptr) { // nullptr batch is for compactions
// 6.1 构建批处理组:合并队列中多个连续的写请求,提高吞吐
WriteBatch* write_batch = BuildBatchGroup(&last_writer);
// 设置序列号并更新last_sequence
WriteBatchInternal::SetSequence(write_batch, last_sequence + 1);
last_sequence += WriteBatchInternal::Count(write_batch);
// 6.2 写入日志和内存表(释放锁执行,减少锁占用时间)
// 释放锁是安全的,因为当前写者是唯一的日志写入者和内存表写入者
{
mutex_.Unlock();
// 先写WAL日志(Write-Ahead Logging),保证持久性
status = log_->AddRecord(WriteBatchInternal::Contents(write_batch));
bool sync_error = false;
// 如果需要同步写入,则调用fsync确保数据落盘
if (status.ok() && options.sync) {
status = logfile_->Sync();
if (!status.ok()) {
sync_error = true;
}
}
// 写入内存表(MemTable)
if (status.ok()) {
status = WriteBatchInternal::InsertInto(write_batch, mem_);
}
mutex_.Lock();
// 处理同步错误:如果日志同步失败,数据库进入不可写状态
if (sync_error) {
// 日志文件状态不确定:刚添加的日志记录在DB重新打开时可能不存在
// 因此强制DB进入一种模式,使所有后续写入都失败
RecordBackgroundError(status);
}
}
// 清理临时批处理
if (write_batch == tmp_batch_) tmp_batch_->Clear();
// 6.3 更新全局序列号
versions_->SetLastSequence(last_sequence);
}
// 7. 处理本批次中的所有写者(从队首到last_writer)
while (true) {
Writer* ready = writers_.front();
writers_.pop_front();
// 将当前批处理的结果状态复制给所有被合并的写者
if (ready != &w) {
ready->status = status;
ready->done = true;
ready->cv.Signal(); // 唤醒等待的写者线程
}
// 到达本批次的最后一个写者,结束循环
if (ready == last_writer) break;
}
// 8. 唤醒新队首(如果队列不为空),开始下一批处理
if (!writers_.empty()) {
writers_.front()->cv.Signal();
}
return status;
}虽然具体每个类是干什么的不知道,至少从这段代码中可以知道 LevelDB 是怎么用锁来处理多线程的写操作的,因为某一时刻可能有多个线程调用 Write 函数
DBImpl中维护了一个writers的写者队列(实际是个 deque),调用Write时先加个锁,将当前WriteBatch封装成Writer丢到队列尾部- 然后进入 while 循环进行等待,直到当前的 writer 已经被完成或变成队首
- 在经过一些基本准备后,将锁释放掉,然后先写 WAL 日志,再写入 MemTable
- 这两个写完后继续加锁,处理本批次中的所有写者
Write函数调用结束后释放锁
提示
总结一下就是通过维护一个写入队列来实现序列化并发写入,只有队首才能实际执行写入操作,在写入的同时还会将多个写请求进行合并,从而提高吞吐
在实际执行写日志和 MemTable 时将锁释放,从而允许其它读操作和后台任务的执行,减少了锁的竞争
下面再看看读操作的实现
Status DBImpl::Get(const ReadOptions& options, const Slice& key,
std::string* value) {
Status s;
// 1. 加锁保护共享数据
MutexLock l(&mutex_);
// 2. 确定读取的快照序列号
SequenceNumber snapshot;
if (options.snapshot != nullptr) {
// 如果指定了快照,使用该快照的序列号
snapshot =
static_cast<const SnapshotImpl*>(options.snapshot)->sequence_number();
} else {
// 否则使用当前最新的序列号
snapshot = versions_->LastSequence();
}
// 3. 获取当前数据库状态的引用
MemTable* mem = mem_; // 可写的内存表
MemTable* imm = imm_; // 不可变的(immutable)内存表
Version* current = versions_->current(); // 当前版本,包含所有SST文件
mem->Ref(); // 增加引用计数,防止被销毁
if (imm != nullptr) imm->Ref();
current->Ref();
bool have_stat_update = false;
Version::GetStats stats; // 用于收集读取统计信息
// 4. 释放锁进行实际读取(减少锁持有时间)
{
mutex_.Unlock();
// 首先在可写内存表中查找
LookupKey lkey(key, snapshot);
if (mem->Get(lkey, value, &s)) {
// 在mem中找到
} else if (imm != nullptr && imm->Get(lkey, value, &s)) {
// 在imm中找到
} else {
// 在磁盘文件(SSTable)中查找
s = current->Get(options, lkey, value, &stats);
have_stat_update = true; // 标记有统计信息需要更新
}
mutex_.Lock();
}
// 5. 如果有读取统计信息,则更新并可能触发压缩
if (have_stat_update && current->UpdateStats(stats)) {
MaybeScheduleCompaction(); // 可能需要安排后台压缩
}
// 6. 释放对数据结构的引用
mem->Unref();
if (imm != nullptr) imm->Unref();
current->Unref();
return s;
}在 Get 中可以看到有 snapshot 这个变量,能够猜测在 LevelDB 中应该是有版本管理的,在后续章节中对这项内容都会逐一进行分析